Computer Translations Have Got Strikingly Better, But Still Need Human Input
This article originally appeared within the Technology Quarterly on The Economist, January 5, 2017.
IN “STAR TREK” it was a hand-held Universal Translator; in “The Hitchhiker’s Guide to the Galaxy” it was the Babel Fish popped conveniently into the ear. In science fiction, the meeting of distant civilisations generally requires some kind of device to allow them to talk. High-quality automated translation seems even more magical than other kinds of language technology because many humans struggle to speak more than one language, let alone translate from one to another.
The idea has been around since the 1950s, and computerised translation is still known by the quaint moniker “machine translation” (MT). It goes back to the early days of the cold war, when American scientists were trying to get computers to translate from Russian. They were inspired by the code-breaking successes of the second world war, which had led to the development of computers in the first place. To them, a scramble of Cyrillic letters on a page of Russian text was just a coded version of English, and turning it into English was just a question of breaking the code.
Scientists at IBM and Georgetown University were among those who thought that the problem would be cracked quickly. Having programmed just six rules and a vocabulary of 250 words into a computer, they gave a demonstration in New York on January 7th 1954 and proudly produced 60 automated translations, including that of “Mi pyeryedayem mislyi posryedstvom ryechyi,” which came out correctly as “We transmit thoughts by means of speech.” Leon Dostert of Georgetown, the lead scientist, breezily predicted that fully realised MT would be “an accomplished fact” in three to five years.
Instead, after more than a decade of work, the report in 1966 by a committee chaired by John Pierce, mentioned in the introduction to this report, recorded bitter disappointment with the results and urged researchers to focus on narrow, achievable goals such as automated dictionaries. Government-sponsored work on MT went into near-hibernation for two decades. What little was done was carried out by private companies. The most notable of them was Systran, which provided rough translations, mostly to America’s armed forces.
La Plume De Mon Ordinateur
The scientists got bogged down by their rules-based approach. Having done relatively well with their six-rule system, they came to believe that if they programmed in more rules, the system would become more sophisticated and subtle. Instead, it became more likely to produce nonsense. Adding extra rules, in the modern parlance of software developers, did not “scale”.
Besides the difficulty of programming grammar’s many rules and exceptions, some early observers noted a conceptual problem. The meaning of a word often depends not just on its dictionary definition and the grammatical context but the meaning of the rest of the sentence. Yehoshua Bar-Hillel, an Israeli MT pioneer, realised that “the pen is in the box” and “the box is in the pen” would require different translations for “pen”: any pen big enough to hold a box would have to be an animal enclosure, not a writing instrument.
How could machines be taught enough rules to make this kind of distinction? They would have to be provided with some knowledge of the real world, a task far beyond the machines or their programmers at the time. Two decades later, IBM stumbled on an approach that would revive optimism about MT. Its Candide system was the first serious attempt to use statistical probabilities rather than rules devised by humans for translation. Statistical, “phrase-based” machine translation, like speech recognition, needed training data to learn from. Candide used Canada’s Hansard, which publishes that country’s parliamentary debates in French and English, providing a huge amount of data for that time. The phrase-based approach would ensure that the translation of a word would take the surrounding words properly into account.
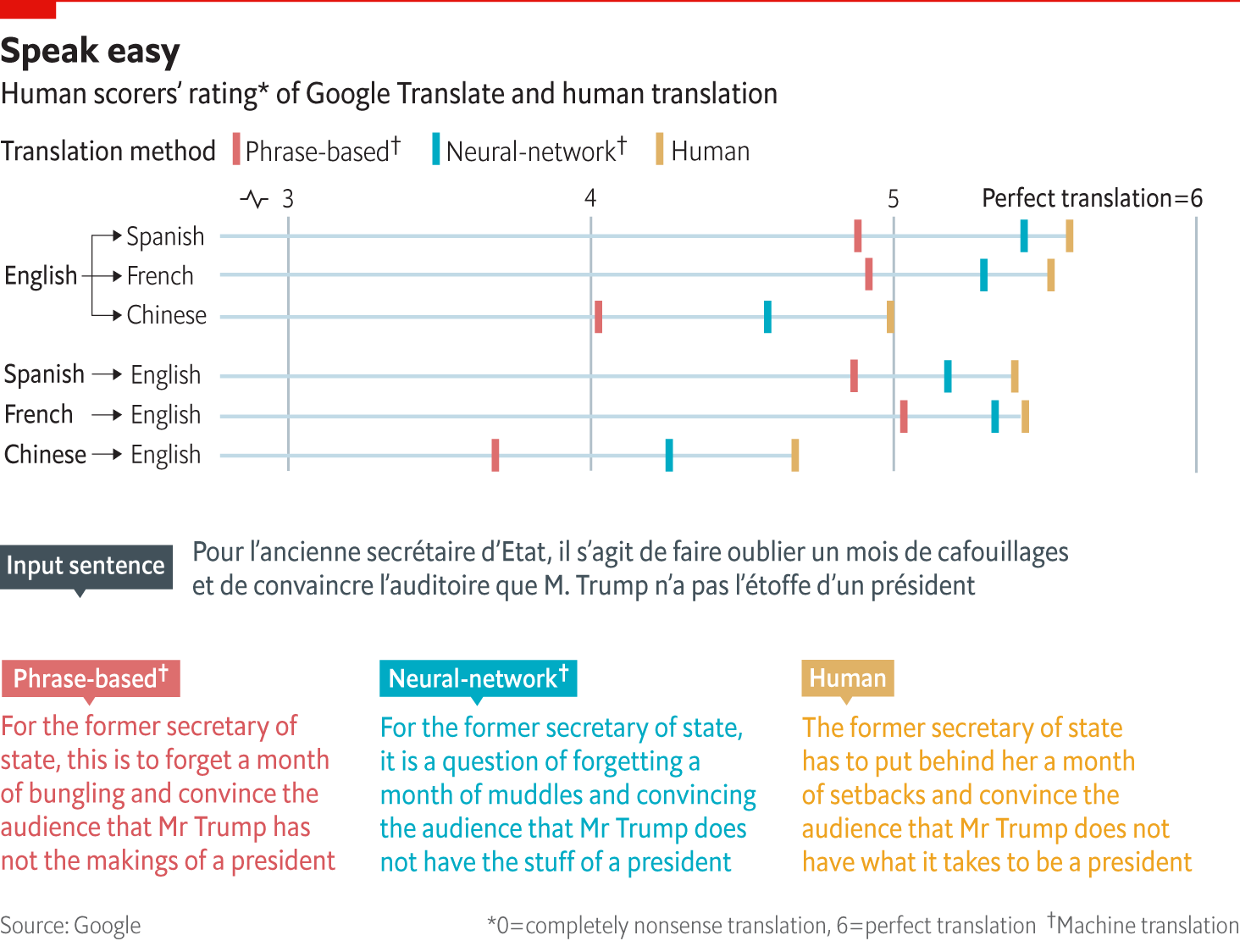
But quality did not take a leap until Google, which had set itself the goal of indexing the entire internet, decided to use those data to train its translation engines; in 2007 it switched from a rules-based engine (provided by Systran) to its own statistics-based system. To build it, Google trawled about a trillion web pages, looking for any text that seemed to be a translation of another—for example, pages designed identically but with different words, and perhaps a hint such as the address of one page ending in /en and the other ending in /fr. According to Macduff Hughes, chief engineer on Google Translate, a simple approach using vast amounts of data seemed more promising than a clever one with fewer data.
Training on parallel texts (which linguists call corpora, the plural of corpus) creates a “translation model” that generates not one but a series of possible translations in the target language. The next step is running these possibilities through a monolingual language model in the target language. This is, in effect, a set of expectations about what a well-formed and typical sentence in the target language is likely to be. Single-language models are not too hard to build. (Parallel human-translated corpora are hard to come by; large amounts of monolingual training data are not.) As with the translation model, the language model uses a brute-force statistical approach to learn from the training data, then ranks the outputs from the translation model in order of plausibility.
Statistical machine translation rekindled optimism in the field. Internet users quickly discovered that Google Translate was far better than the rules-based online engines they had used before, such as BabelFish. Such systems still make mistakes—sometimes minor, sometimes hilarious, sometimes so serious or so many as to make nonsense of the result. And language pairs like Chinese-English, which are unrelated and structurally quite different, make accurate translation harder than pairs of related languages like English and German. But more often than not, Google Translate and its free online competitors, such as Microsoft’s Bing Translator, offer a usable approximation.
Such systems are set to get better, again with the help of deep learning from digital neural networks. The Association for Computational Linguistics has been holding workshops on MT every summer since 2006. One of the events is a competition between MT engines turned loose on a collection of news text. In August 2016, in Berlin, neural-net-based MT systems were the top performers (out of 102), a first.
Now Google has released its own neural-net-based engine for eight language pairs, closing much of the quality gap between its old system and a human translator. This is especially true for closely related languages (like the big European ones) with lots of available training data. The results are still distinctly imperfect, but far smoother and more accurate than before. Translations between English and (say) Chinese and Korean are not as good yet, but the neural system has brought a clear improvement here too.
The Coca-Cola Factor
Neural-network-based translation actually uses two networks. One is an encoder. Each word of an input sentence is converted into a multidimensional vector (a series of numerical values), and the encoding of each new word takes into account what has happened earlier in the sentence. Marcello Federico of Italy’s Fondazione Bruno Kessler, a private research organisation, uses an intriguing analogy to compare neural-net translation with the phrase-based kind. The latter, he says, is like describing Coca-Cola in terms of sugar, water, caffeine and other ingredients. By contrast, the former encodes features such as liquidness, darkness, sweetness and fizziness.
Once the source sentence is encoded, a decoder network generates a word-for-word translation, once again taking account of the immediately preceding word. This can cause problems when the meaning of words such as pronouns depends on words mentioned much earlier in a long sentence. This problem is mitigated by an “attention model”, which helps maintain focus on other words in the sentence outside the immediate context.
Neural-network translation requires heavy-duty computing power, both for the original training of the system and in use. The heart of such a system can be the GPUs that made the deep-learning revolution possible, or specialised hardware like Google’s Tensor Processing Units (TPUs). Smaller translation companies and researchers usually rent this kind of processing power in the cloud. But the data sets used in neural-network training do not need to be as extensive as those for phrase-based systems, which should give smaller outfits a chance to compete with giants like Google.
Fully automated, high-quality machine translation is still a long way off. For now, several problems remain. All current machine translations proceed sentence by sentence. If the translation of such a sentence depends on the meaning of earlier ones, automated systems will make mistakes. Long sentences, despite tricks like the attention model, can be hard to translate. And neural-net-based systems in particular struggle with rare words.
Training data, too, are scarce for many language pairs. They are plentiful between European languages, since the European Union’s institutions churn out vast amounts of material translated by humans between the EU’s 24 official languages. But for smaller languages such resources are thin on the ground. For example, there are few Greek-Urdu parallel texts available on which to train a translation engine. So a system that claims to offer such translation is in fact usually running it through a bridging language, nearly always English. That involves two translations rather than one, multiplying the chance of errors.
Even if machine translation is not yet perfect, technology can already help humans translate much more quickly and accurately. “Translation memories”, software that stores already translated words and segments, first came into use as early as the 1980s. For someone who frequently translates the same kind of material (such as instruction manuals), they serve up the bits that have already been translated, saving lots of duplication and time.
A similar trick is to train MT engines on text dealing with a narrow real-world domain, such as medicine or the law. As software techniques are refined and computers get faster, training becomes easier and quicker. Free software such as Moses, developed with the support of the EU and used by some of its in-house translators, can be trained by anyone with parallel corpora to hand. A specialist in medical translation, for instance, can train the system on medical translations only, which makes them far more accurate.
At the other end of linguistic sophistication, an MT engine can be optimised for the shorter and simpler language people use in speech to spew out rough but near-instantaneous speech-to-speech translations. This is what Microsoft’s Skype Translator does. Its quality is improved by being trained on speech (things like film subtitles and common spoken phrases) rather than the kind of parallel text produced by the European Parliament.
Translation management has also benefited from innovation, with clever software allowing companies quickly to combine the best of MT, translation memory, customisation by the individual translator and so on. Translation-management software aims to cut out the agencies that have been acting as middlemen between clients and an army of freelance translators. Jack Welde, the founder of Smartling, an industry favourite, says that in future translation customers will choose how much human intervention is needed for a translation. A quick automated one will do for low-stakes content with a short life, but the most important content will still require a fully hand-crafted and edited version. Noting that MT has both determined boosters and committed detractors, Mr Welde says he is neither: “If you take a dogmatic stance, you’re not optimised for the needs of the customer.”
Translation software will go on getting better. Not only will engineers keep tweaking their statistical models and neural networks, but users themselves will make improvements to their own systems. For example, a small but much-admired startup, Lilt, uses phrase-based MT as the basis for a translation, but an easy-to-use interface allows the translator to correct and improve the MT system’s output. Every time this is done, the corrections are fed back into the translation engine, which learns and improves in real time. Users can build several different memories—a medical one, a financial one and so on—which will help with future translations in that specialist field.
TAUS, an industry group, recently issued a report on the state of the translation industry saying that “in the past few years the translation industry has burst with new tools, platforms and solutions.” Last year Jaap van der Meer, TAUS’s founder and director, wrote a provocative blogpost entitled “The Future Does Not Need Translators”, arguing that the quality of MT will keep improving, and that for many applications less-than-perfect translation will be good enough.
The “translator” of the future is likely to be more like a quality-control expert, deciding which texts need the most attention to detail and editing the output of MT software. That may be necessary because computers, no matter how sophisticated they have become, cannot yet truly grasp what a text means.